Hier wird gezeigt, wie in R Twitterdaten zu einfachen Wordclouds verarbeitet werden können. Wordclouds visualisieren die Häufigkeit von Wörtern, die mit einem bestimmten Wort (einem Hashtag oder Suchbegriff) zusammen genannt werden.
Die Basis für die Visualisierung sind Daten, die über die Rest-API von Twitter abgerufen werden (Siehe: https://statistics.ohlsen-web.de/twitter-mining-teil1/).
#-----------------------------------------------------
# --- Mit Twitter verbinden ---
#-----------------------------------------------------
library(twitteR)
# Authentifizierungsschlüssel eingeben
api_key <- "**************************"
api_secret <- "***************************"
access_token <- "*****************************"
access_token_secret <- "******************************"
setup_twitter_oauth(api_key,api_secret,access_token,access_token_secret)
#--- Suchabfrage: 450 tweets mit dem Hashtag #rstats ---
tweets<-searchTwitter("christmas",n=450))
tweets
Textkorpus für Wordcloud erstellen
Die Datenbasis für die Wordcloud haben wir jetzt. Jetzt benötigen wird die tm-library (textmining), um den Wortkorpus zu erstellen. Anschließend wird mit der wordcloud-library die Häufigkeit als Wordcloud erstellt. Das Paket RColorBrewer bietet verschiedene Farbschemas an, die genutzt werden können, wenn die Standardfarbgebung nicht gefällt.
Den Code für die Wordcloud habe ich von hier https://sites.google.com/site/miningtwitter/questions/talking-about/wordclouds/wordcloud1
library(tm)
library(wordcloud)
library(RColorBrewer)
#Tweet-Text extrahieren
tweet.tex<-sapply(tweets, function(x) x$getText())
#Aufgrund von emoticons &co gibt es manchmal probleme.
#Das liegt daran, dass wir eine UTF-8 Codierung nutzen, viele chinesische Symbole, mathematische Symbole und Emoji-icons #länger als 4 bytes sind und zudem keine kleingeschriebene Variante enthalten.
#Hier ist ein Workaround, um solche Zeichen zu übergehen:
http://gastonsanchez.com/blog/how-to/2012/05/29/Catching-errors-when-using-tolower.html
tryTolower = function(x)
{
# create missing value
# this is where the returned value will be
y = NA
# tryCatch error
try_error = tryCatch(tolower(x), error = function(e) e)
# if not an error
if (!inherits(try_error, "error"))
y = tolower(x)
return(y)
}
tweet.text<-sapply(tweet.text, function(x) tryTolower(x))
## Wortkorpus erstellen
tweet.corpus<-Corpus(VectorSource(enc2utf8(tweet.text)))
# removing numbers, punctuation symbols, lower case, etc.
tdm = TermDocumentMatrix(tweet.corpus, control = list(removePunctuation = TRUE, stopwords = c("follow"),removeNumbers = TRUE, tolower = TRUE))
#Worthäufigkeiten ermitteln
# define tdm as matrix
m = as.matrix(tdm)
# get word counts in decreasing order
word_freqs = sort(rowSums(m), decreasing=TRUE)
# create a data frame with words and their frequencies
dm = data.frame(word=names(word_freqs), freq=word_freqs)
Grafik plotten
wordcloud(dm$word, dm$freq, random.order=FALSE, colors=brewer.pal(8, "Dark2"))
Im Code für die TermDocumentMatrix gibt es das „stopwords(kind = „en“)“-Argument. Stopwords sind Worte, die aus der Wordcloud ausgeschlossen werden sollen, weil sie so häufig vorkommen und daher nicht informativ sind. Stopwords sind für verschiedene Sprachen verfügbar (danish, dutch, english, finnish, french, german, hungarian, italian, norwegian, portuguese, russian, spanish, and swedish).
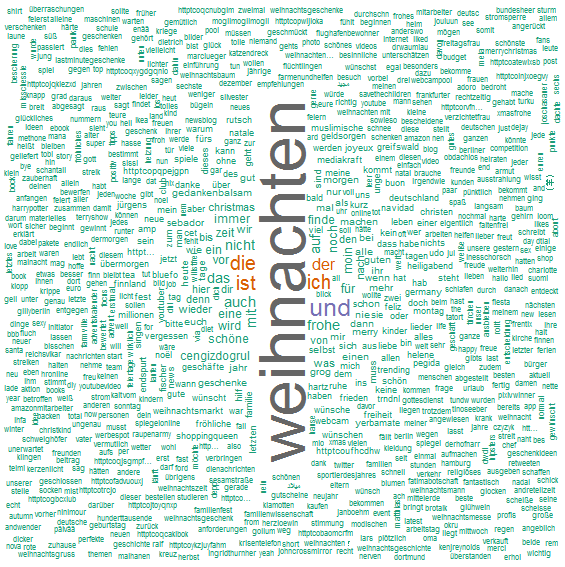
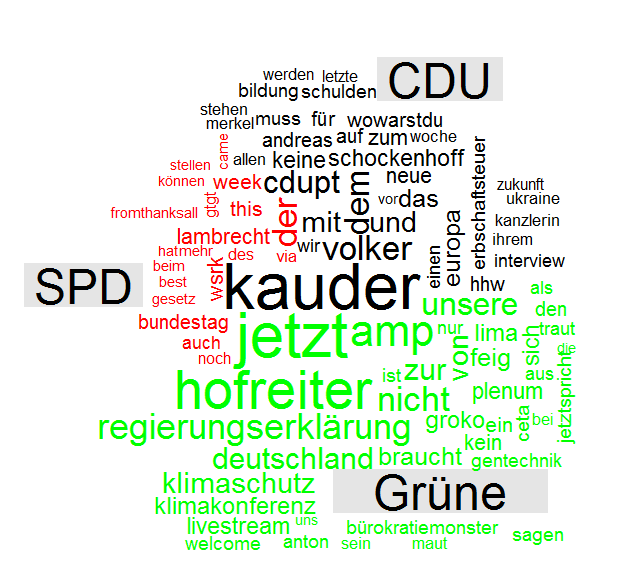
Worthäufigkeiten aus 3000 Tweets zum Begriff „Weihnachten“
Wenn die Wordcloud zuviele einzelne Nennungen enthält, kann man z.B. mit min.freq=3 festlegen, dass nur Wörter angezeigt werden, die mindestens drei mal in der Wortliste enthalten sind.
wordcloud(dm$word, dm$freq, random.order=FALSE, colors=brewer.pal(3, "Dark2"),min.freq=3,max.words=100)
png("c:/wordcloud.png", width=800,height=800)

Nur Wörter, die mindestens 3 mal genannt wurden.
Mehrfache Berücksichtigung von Accounts
Mir ist aufgefallen, dass die Häufigkeit mancher Wörter aus Retweets resultiert. Besonders die jugendlichen Follower/Fans von bekannten Youtubern wie der Slimani-Familie scheinen Weltmeister im Retweeten jeder noch so kleinen Äußerung ihrer Vorbilder zu sein. Dieses Problem kann auch durch sogenannte „Retweet-Bots“ entstehen, die automatisiert alle Tweets mit einem bestimmten Wortinhalt retweeten.
Möglicherweise möchte man solche Accounts aus der Wordcloud ausfiltern. Zur Demonstration hier eine Grafik mit den TwitterAccounts, die durch Retweets den größten Anteil an der Wordcloud haben.
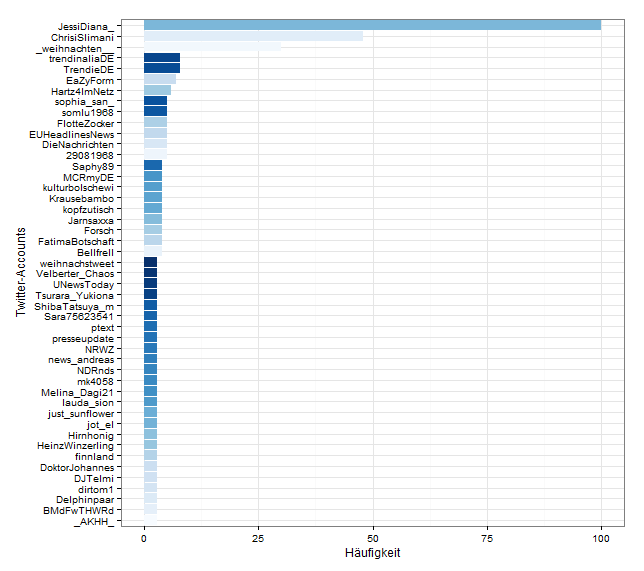
Die Daten wurden nach Häufigkeit absteigend sortiert und anschließend die Top 5% ausgewählt.
Hier der R-Code für die Grafik
#-----------------------------------------------------
# --- Welche Accounts haben den höchsten Anteil an den tweets
#-----------------------------------------------------
library(dplyr)
library(ggplot2)
#rohtweets zu dataframe umwandeln
tweets.df<-twListToDF(tweets)
counts<-as.data.frame(table(tweets.df$screenName))
#Mit dplyr nach Häufigkeit sortieren und top 5% auswählen
counts<- counts %>% arrange(desc(Freq)) %>% filter(cume_dist(desc(Freq)) < 0.05)
#erweiterte Farbpalette(Quelle: http://novyden.blogspot.de/2013/09/how-to-expand-color-palette-with-ggplot.html)
library(RColorBrewer)
colourCount<-length(unique(counts$Var1))
myPalette<-colorRampPalette(brewer.pal(9, "Blues"))
#counts<-as.factor(counts$Freq)
ggplot(counts, aes(reorder(Var1, Freq),Freq,fill=Var1)) + geom_bar(stat="identity") + coord_flip()+ theme_bw()+theme(legend.position="none") + xlab("Twitter-Accounts") + ylab("Häufigkeit") + scale_fill_manual(values = myPalette(colourCount))
Hier geht es weiter mit Teil 3 – Comparison Wordclouds.