
Seit es das R-Package dplyr gibt, sind viele Aufgaben bei der Datenbearbeitung einfacher geworden. Soll diesselbe Umformung für viele Variablen durchgeführt werden, kann es eine Menge Tipparbeit sparen, wenn man den Code in eine Funktion packt.
Bei der Arbeit mit dplyr ist es wichtig, dass man plyr – sofern man es benötigt – grundsätzlich als erstes läd. Andernfalls treten mit Sicherheit an irgendeinem Punkt der Arbeit Fehlermeldungen auf. Summarise() gibt es beispielsweise in plyr, aber auch in dplyr, was zu Konflikten wie diesem führt: „Error in n() : This function should not be called directly„.
# Installieren der nötigen Pakete
install.packages("plyr")
install.packages("dplyr")
install.packages("tidyr")
install.packages("lazyeval") #oder: devtools::install_github("hadley/lazyeval")
library("plyr")
library("dplyr")
library("tidyR")
library("lazyeval")
Was macht dplyr so besonders?
Dplyr-Code ist einfach lesbar, logisch und arbeitet sequenziell, da es den Pipe-Operator %>% aus aus dem MagrittR-Package nutzt.
Durch „%>%“ (sprich: then) können Manipulationen in einer intuitiven Reihenfolge ausgeführt werden. Während früher eine Funktion umständlich mit verschachtelten Klammern zu schreiben war, kann man mit dplyr einfach der Intuition folgen und einen Schritt nach dem nächsten machen.
Ein einfaches Beispiel: Ich möchte alle Personen eines Datensatzes entsprechend der Kategorien einer Variable in Gruppen einteilen (z.B. Geschlecht, Einkommensstufe, Postleitzahl) und dann die Anzahl der Personen je Kategorie bestimmen. Ich wähle den dataframe aus und gebe ihn mit dem Pipe-Operator (%>%) an die group_by() Funktion von dplyr weiter. Anschließend wird der gruppierten Datensatz an die summarise()-Funktion weitergegeben, die dann mit n() die Fälle zählt. Das Ergebnis wird als dataframe-Objekt „Beispiel“ abgelegt.
Durch group_by() werden Gruppen erzeugt und mittels summarise() werden die Daten je Gruppe so aggregiert, wie ich angebe. Hier wird nur n() je Gruppe gezählt.
Beispiel<-dataframe %>%
group_by(variable) %>%
summarise(
freq = n()
)
Dies ist natürlich nur Minimalbeispiel. Um einen Eindruck davon zu bekommen, was dplyr alles kann, empfehle ich folgenden Überblick:
Data Wrangling with dplyr und tidyr Cheat Sheet.
95% aller Aufgaben, die das Umformen von Daten, erstellen neuer Variablen, Gruppieren von Daten, Auswählen von Fällen, Variablen, Werten, oder Zusammenfügen von Datensätzen erfordern, können damit erledigt werden. Und: Alle diese Schritte können miteinander kombiniert werden.
dplyr in Funktionen
Versucht man den obigen dplyr-code in eine Funktion zu schreiben, stößt man auf eine Fehlermeldung. Warum? Innerhalb von Funktionen muss eine andere Version der dplyr-Funktionen verwendet werden: Standard evaluation (SE)
- Anstatt summarise() ==> summarise_()
- Anstatt mutate() ==> mutate_()
- Anstatt filter() ==> filter_()
- usw.
Zusätzlich zu diesen SE-Versionen von dplyr-Funktionen ist die Übergabe der Input-Objekte an die Funktion leicht unterschiedlich. Entweder müssen die Objekte
- als Formel „~ Objekt“
- als „quote(Objekt)“
- oder als String mit Anführungszeichen “ ‚Objekt‘ „
eingefügt werden. Hadley Wickham, der Programmierer des Pakets, empfiehlt die erste Möglichkeit.
Als Funktion sieht der obige dplyr-code so aus:
test.function <- function(dataframe, variable){
dataframe %>%
group_by_(variable) %>%
summarise_(
freq = ~n()
)
}
#Aufrufen der Funktion für den test_dataframe und die Variable gender
test<-test.function(test_dataframe, ~gender)
Die Funktion „test.function(x,y) kann zwei Input-Objekte annehmen, für die sie den dplyr-code durchführt und das Ergebnis als „test“-dataframe abspeichert.
Komplexeres Beispiel
Es ist möglich, ganze Auswertungsprozeduren als Funktion zusammenzufassen. Der folgende Code führt eine Gewichtung durch, bildet Anteilswerte der Antworten und generiert einen Plot der Daten.
#Funktion zur Berechnung der gewichteten Anteilswerte
weighting.function <- function(dataframe, variable){
dataframe %>%
group_by_(variable) %>%
summarise_(
freq = ~n(),
freq_weighted = ~sum(weight)
) %>%
mutate_(
perc=~freq/sum(freq)*100,
perc_weighted=~freq_weighted/sum(freq_weighted)*100
) %>%
gather(key=Gewichtung,value=Wert,perc:perc_weighted)
}
#Ausführen der Funktion
gender_w<-weighting.function(datensatz, ~gender)
# Plotten der Daten mit ggplot2
library("ggplot2")
ggplot(gender_w) + geom_bar(aes(x=gender,y=Wert), stat="identity") + facet_grid(~Gewichtung) +scale_x_discrete(labels=c("männlich","weiblich","NA"))+ ggtitle("Anteilswerte Geschlecht - gewichtet und ungewichtet")
Das Ergebnis: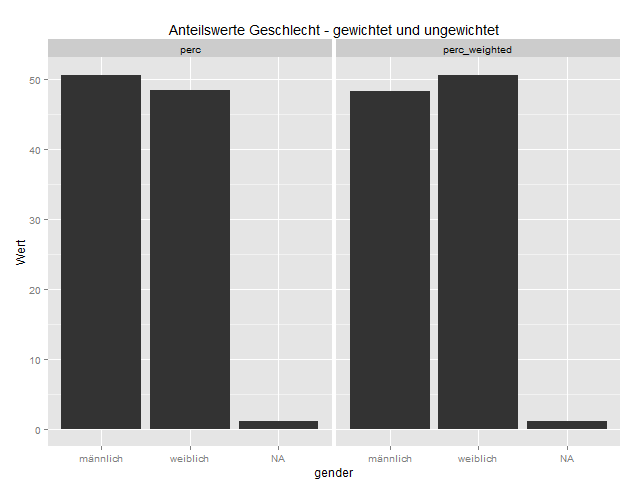
An diesem Plot sieht man, dass vor der Gewichtung der Anteil der Männer etwas höher war, während bei den gewichteten Daten der Frauenanteil etwas erhöht wird. Da es in der Sozialstruktur Deutschlands etwas mehr Frauen als Männer gibt (hauptsächlich wegen der höheren Lebenserwartung), spiegeln die gewichteten Daten die Grundgesamtheit etwas besser wider.
Hier gibt es Weitere Informationen zu standard evaluation in dplyr
Und über die R-Console gelangt man an die vignette: vignette(„tidy-data“).