
Im letzten Blogeintrag (Teil 2) wurden die Ergebnisse einer Twitter-Suche als Wordcloud visualisiert. Man kann das Potential von Wordclouds noch etwas weiter ausschöpfen, wenn man Wordclouds miteinander vergleicht. Das folgende Beispiel orientiert sich an dem code von dieser Seite.
Wie immer, brauchen wir zuerst die Verbindung zwischen R und der Twitter-API.
#-----------------------------------------------------
# --- Mit Twitter verbinden ---
#-----------------------------------------------------
library(twitteR)
# Authentifizierungsschlüssel eingeben
api_key <- "**************************"
api_secret <- "***************************"
access_token <- "*****************************"
access_token_secret <- "******************************"
setup_twitter_oauth(api_key,api_secret,access_token,access_token_secret)
#--- Suchabfrage: 450 tweets mit dem Hashtag #rstats ---
tweets<-searchTwitter("christmas",n=450))
tweets
Comparison Wordcloud
Als Beispiel werde ich die Tweets der Bundestagsfraktionen von CDU, SPD und den Grünen abgreifen und jeweils einen Textkorpus erstellen, der dann zusammengefügt in einer einzelnen Wordcloud visualisiert wird. Jede Partei wird eine Wordcloud ihrer Farbe erhalten. Dadurch kann vielleicht ein Einblick erhalten werden, über welche inhaltlichen Schwerpunkte die Parteien jeweils am häufigsten twittern.
#Twitter Accounts der Bundestagsfraktionen CDU/CSU, SPD, Gruene(wordcloud)
library(tm)
library(wordcloud)
cdu.tweets<-userTimeline("CDUCSUBT",n=500)
spd.tweets<-userTimeline("SPDBT",n=500)
gruene.tweets<-userTimeline("GrueneBundestag",n=500)
# get text
cdu_txt = sapply(cdu.tweets, function(x) x$getText())
spd_txt = sapply(spd.tweets, function(x) x$getText())
gruene_txt = sapply(gruene.tweets, function(x) x$getText())
#text cleanings
clean.text = function(x)
{
# tolower
x = tolower(x)
# remove rt
x = gsub("rt", "", x)
# remove at
x = gsub("@\\w+", "", x)
# remove punctuation
x = gsub("[[:punct:]]", "", x)
# remove numbers
x = gsub("[[:digit:]]", "", x)
# remove links http
x = gsub("http\\w+", "", x)
# remove tabs
x = gsub("[ |\t]{2,}", "", x)
# remove blank spaces at the beginning
x = gsub("^ ", "", x)
# remove blank spaces at the end
x = gsub(" $", "", x)
return(x)
}
cdu_clean = clean.text(cdu_txt)
spd_clean = clean.text(spd_txt)
gruene_clean = clean.text(gruene_txt)
#join text
cdu = paste(cdu_clean, collapse=" ")
spd = paste(spd_clean, collapse=" ")
gruen = paste(gruene_clean, collapse=" ")
# put everything in a single vector
all = c(cdu, spd, gruen)
Die Daten sind nun vorbereitet und können geplottet werden.
An dem Punkt, an dem die TermDocumentMatrix erstellt wird, werden mittels „stopwords(„german“) häufig genannte deutsche Wörter („der“, „die“, „das“, „und“…) von der Auswertung ausgeklammert.
#WORDCLOUD COMPARISON
# create corpus
corpus = Corpus(VectorSource(all))
# create term-document matrix
tdm = TermDocumentMatrix(corpus, control = list(removePunctuation = TRUE, stopwords = stopwords("german"),removeNumbers = TRUE))
# convert as matrix
tdm = as.matrix(tdm)
# add column names
colnames(tdm) = c("CDU", "SPD", "Grüne")
#PLOTTING
# comparison cloud
comparison.cloud(tdm, random.order=FALSE, colors = c("black", "red", "green"),max.words=100)
Die untenstehende Grafik ist das Ergebnis. Während bei der CDU/CSU-Fraktion häufig der Fraktionsvorsitzende Kauder erwähnt wird sowie der Nachruf auf „Schockenhoff“ viel Raum einnimmt, werden auch „Europa“, „Erbschaftssteuer“, „Ukraine“ und „Europa“ genannt. Auch bei den Grünen wird der Fraktionsvorsitzende (Hofreiter) am häufigsten genannt. Ansonsten ist die Klimakonferenz in Lima scheinbar ein Hauptthema. Der Twitteraccount der SPD-Bundestagsfraktion scheint ein breites Themenrepertoire zu haben, da sich keine einzelnen thematischen Schwerpunkte abheben. Jedoch zeigt sich wie bei der CDU und den Grünen, dass die Fraktionsvorsitzende Lambrecht häufig genannt wird.
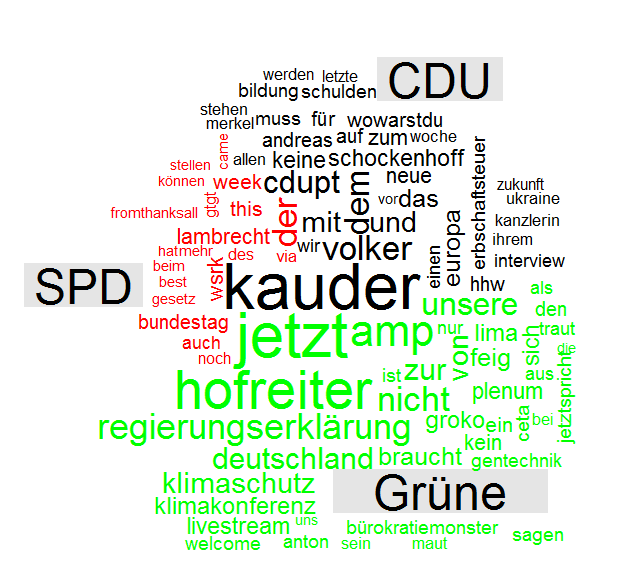
Comparison Wordcloud. Tweets der Accounts der CDU, SPD und Grünen Bundestagsfraktion (je 450 tweets)
Commonality Cloud
Eine Alternative zur Comparison Wordcloud ist die Commonality Cloud. Sie wird ebenfalls mit der wordcloud-library erstellt.
# commonality cloud commonality.cloud(tdm, random.order=FALSE, colors = brewer.pal(8, "Dark2"),title.size=1.5)
Leider kristalliert sich in der Commonality Cloud kaum Übereinstimmung ab. Eventuell sollten mehr Tweets abgegriffen und häufige Wörter wie „die, der, das“ aus der Analyse ausgeschlossen werden.

Jeweils 450 letzte Tweets der Accounts der CDU, SPD und Grünen Bundestagsfraktion als Commonality Cloud
Im nächsten Blogeintrag (Teil 4) zeige ich, wie eine einfache Sentiment Analysis mit Tweets durchgeführt werden kann.