Der letzte Blogeintrag (Teil 5) zeigte ein einfaches Rezept, um eine Followermap zu erstellen.
Hier möchte ich ein Beispiel zeigen, in dem ich die Tweethäufigkeit zu einem Hashtag über einen Zeitraum visualisiere. Konkret möchte ich die Tweets zum Fußballspiel von Werder-Bremen gegen Hannover96 nutzen. Wann wird am meisten getwittert? Wenn etwas spannendes auf dem Spielfeld passiert (Tor, gelbe Karte, Freistoß)? Oder überwiegend vor und nach dem Spiel beziehungsweise in der Halbzeitpause, wenn das Spiel keine Aufmerksamkeit erfordert?
Folgende Schritte sind nötig:
- Verbindung zur Twitter-(Streaming)-API herstellen und relevante Tweets speichern.
- Spielereignisse und ihre Zeitpunkte von Liveticker abgreifen und als Tabelle abspeichern
- Daten formatieren/bereinigen, aggregieren und für Grafik vorbereiten
- Daten mit ggplot2 plotten
Verbindung zur Streaming-API
Wie immer: Zunächst eine Verbindung mit der Twitter-API herstellen. In diesem Fall mit der Streaming-API, was einen etwas anderen Code erfordert, als die Rest-API
#-----------------------------------------------------
# --- Mit Twitter verbinden ---
#-----------------------------------------------------
library(RCurl)
library(ROAuth)
library(twitteR)
library(streamR)
# Authentifizierungsschlüssel eingeben
api_key <- "**************************"
api_secret <- "***************************"
access_token <- "*****************************"
access_token_secret <- "******************************"
options(RCurlOptions = list(cainfo = system.file("CurlSSL", "cacert.pem", package = "RCurl")))#nicht für MAC/Linux-User
my_oauth consumerSecret=api_secret,
requestURL='https://api.twitter.com/oauth/request_token',
accessURL='https://api.twitter.com/oauth/access_token',
authURL='https://api.twitter.com/oauth/authorize')
my_oauth$handshake(cainfo = system.file("CurlSSL", "cacert.pem", package = "RCurl"))
Mit dem Ausführen der letzten Codezeile öffnet sich ein Browserfenster und zeigt eine PIN an. Diese PIN muss nun in die R-console eingegeben werden, um die Verbindung herzustellen.
Tweets während des Fußballspiels speichern
Nun soll der Twitter-Datenstream zu den Suchbegriffen „Werder“,“H96″ und „SVWH96“ abgespeichert werden. Die ersten beiden Suchbegriffe stehen natürlich für die Mannschaften. Der dritte Begriff ist das Hashtag für das Bundeligaspiel. Es hat sich eingebürgert, beide Kürzel der Mannschaften in einem Hashtag zu kombinieren, wobei die Heimatmannschaft zuerst genannt wird. Die Suchbegriffe werden im untenstehenden Code mit dem Argument „track“ als Komma-separierte Liste festgelegt. So werden Tweets gespeichert, die mindestens einen der Begriffe enthalten. Das Komma entspricht dem logischen „OR“. Lässt man es weg, sind die Begriffe wie beim logischen „AND“ verknüpft.
Ich habe mich für die Streaming-API entschieden, da ich hierdurch wesentlich mehr Tweets erhalte. Die Streaming-API greift die Tweets fortlaufend ab. Deshalb muss ich den Zeitraum festlegen, für den ich Tweets haben möchte. Die Tweets sollen 6 Stunden lang aufgezeichnet werden. Dies lege ich mit dem Wert 21600 im timeout-Argument fest (21600 = 6 x 60min x 60sek).
#Tweets abgreifen
filterStream(file.name="C:/Beispieldaten/svwh96b.json", track=c("svwh96","Werder","H96"), timeout=21600, oauth=my_oauth)
#Tweets in Dataframe packen
tweets_svw <- parseTweets("C:/Beispieldaten/svwh96b.json", verbose = TRUE)
Spielereignisse in Tabelle speichern
Nachdem wir die Tweets haben, möchten wir nun eine Tabelle mit den Spielereignissen erstellen. Am einfachsten ist es, eine Liveticker-Tabelle von einer Sport-Homepage zu kopieren, in eine Tabellenkalkulation (Excel, LibreOfficeCalc, Numbers) einzufügen und als .csv-Datei zu speichern.
Es geht natürlich auch komplizierter. Der untenstehende Code zeigt, wie „rvest“ (ein Webscraping-tool von Hadley Wickham) genutzt werden kann, um Daten von Websiten zu holen. Der Code zeigt nur den Ansatz, das Data-cleaning habe ich nicht eingefügt.
#--------------------------------------------------------------------------
# --- Webscraping der Spielverlauf-Tabelle
#--------------------------------------------------------------------------
install.packages("rvest")
library(rvest)
#Website parsen und anschließend, den interessierenden TEXT extrahieren
spielbericht<- html("http://www.weser-kurier.de/werder/werder-bundesliga_artikel,-Unentschieden-im-Weserstadion-_arid,1013156.html")
Spielverlauf1<-as.character(spielbericht %>% html_nodes("p") %>% html_text())
Spielverlauf2<-as.character(spielbericht %>% html_nodes("strong") %>% html_text())
#Vector in Minute und Ereignis trennen und als dataframe speichern
library(reshape2)
Spielverlauf<-colsplit(Spielverlauf," ",c("Minute","Ereignis"))
#hier beginnt dann das Datacleaning.
Daten für Visualisierung vorbereiten
Ich habe oben zwei dataframes erzeugt: Einen dataframe mit den tweets über 6 Stunden, den anderen dataframe mit den wichtigsten Spielereignissen und den entsprechenden Spielminuten.
tweets_svw<-read.csv(file='c:/Beispieldaten/svwh96_streamR.csv', header=T)
Spielverlauf<-read.csv2(file="C:/Beispieldaten/Spielereignisse.csv",sep=";",header=FALSE,col.names=c("Minute","Ereignis"))
Eine schöne Sache von R ist, dass Zeit- und Datumsangaben eine eigene Klasse (class) besitzen. Die Klasse legt fest, wie mit den Daten umgegangen werden soll. Sehr vereinfacht, wissen Pakete wie GGPlot2 durch die Klasse „ah, wenn ich auf 15:30 Uhr 40 Minuten addiere, ist es 16:10 Uhr und nicht 15:70Uhr.“
Konkret nutze ich die Klasse POSIXct. Sie ist hilfreich, wenn Zeiten in dataframes gespeichert werden sollen. POSIXlt wäre die Alternative. Doch sie nutzt man eher, wenn es um Dinge wie Wochentage oder ähnliches geht.
Der Befehl „strptime“ ist nützlich, wenn die Daten noch nicht im Format der entsprechenden Klasse vorliegen (sondern z.B. als character vector) und noch umformatiert werden müssen.
Zeitformat der Tweets anpassen
Im tweets_svw dataframe gibt es eine Spalte namens „created_at“, welche den Zeitpunkt enthält, an dem ein Tweet geschrieben wurde. Diese Einträge sehen so aus: „Sat Dec 13 13:04:34 +0000 2014“. Um diese Daten als Zeitangabe nutzbar zu machen, konvertiere ich sie ins POSIXct-Format.
#Datenformat (musste ich bei mir anpassen)
Sys.setlocale("LC_TIME", "English")
## Zeitformat der created_at-Variable auf POSIXct ändern
tweets_svw$Zeitformat <- as.POSIXct(tweets_svw$created_at, format = "%a %b %d %H:%M:%S %z %Y", tz="")
head(tweets_svw$Zeitformat)
[/code]
<strong>Zeitformat der Spielereignisse anpassen</strong>
Der Liveticker enthielt nur die Spielereignisse und die entsprechende Spielminute (0-92). Die Zeitangaben sollen aber in beiden dataframes im gleichen Format sein, daher muss ich die Spielminuten in Uhrzeiten umwandeln. Mit der POSIXct Klasse ist dies möglich. Der Anstoß war um 15:30. Hier müssen nun noch die Spielminuten aufaddiert werden.
[code language="r"]
Spielverlauf$Uhrzeit<-c("2014-12-13 15:30:00")
Spielverlauf$Uhrzeit<- as.POSIXct(Spielverlauf$Uhrzeit,tz="")
Spielverlauf$Minute<- (Spielverlauf$Minute*60)
Spielverlauf$Uhrzeit<-Spielverlauf$Uhrzeit + Spielverlauf$Minute
head(Spielverlauf$Uhrzeit)
Anmerkung: Bei der Berechnung der Zeitpunkte für die Spielereignisse habe ich einen Fehler gemacht, da ich nicht berücksichtigt habe, dass die Halbzeit ebenfalls Zeit verbraucht.
Tweets pro Minute aggregieren
Mich interessiert nicht der Inhalt der Tweets, sondern ihre Häufigkeit vor, während und nach dem Spiel. Daher habe ich mich entschieden, zu zählen, wieviele Tweets pro Minute geschrieben wurden.
Der Code hierfür ist nicht wirklich schön und eventuell werde ich ihn nochmal aktualisieren, aber für den Moment macht er erstmal das, was ich möchte.
In Teil 1.) erzeuge ich einen neuen dataframe, der nur die Uhrzeit des abgesetzten Tweets enthält, sowie eine zweite Spalte mit einer „1“ als Zähler, um im nächsten Schritt die Tweets je Minute zu zählen.
In Teil 2.) zerstückele ich den dataframe nach Minuten, zähle die Tweets je Minute und bekomme am Ende einen neuen dataframe namens plot.df. In plot.df ist eine minutengenaue Zeitangabe (Uhrzeit) und die Anzahl der Tweets (Freq) in dieser Minute enthalten.
# 1.)
tweets.df<-as.data.frame(tweets_svw$Zeitformat) #neuer dataframe
tweets.df$freq<-1 #jeder Tweet erhält einen Häufigkeitszähler
colnames(tweets.df)<-c("time","freq")
tweets.df$time <- as.POSIXct(tweets.df$time)
# 2.)
#Tweets pro Minute aggregieren und als Dataframe abspeichern
by.mins <- cut.POSIXt(tweets.df$time,"mins")
tweets.mins <- split(tweets.df, by.mins)
plot.df<-sapply(tweets.mins,function(x)sum(as.integer(x$freq)))
plot.df<-as.data.frame(plot.df)
plot.df<-cbind(Uhrzeit = rownames(plot.df), plot.df)
plot.df$Uhrzeit <- as.POSIXct(plot.df$Uhrzeit)
plot.df<-as.data.frame(plot.df)
names(plot.df)[names(plot.df) == 'plot.df'] <- 'Freq'
Die Vorbereitungen sind jetzt fast abgeschlossen. Wir müssen nur noch eine unnütze Spalte aus den dataframes loswerden und vorsichtshalber nochmal das Datumsformat festlegen.
library(dplyr)
plot.df<- plot.df %>% select(Uhrzeit,Freq)
Spielverlauf<- Spielverlauf %>% select(Uhrzeit,Ereignis)
plot.df$Uhrzeit<-as.POSIXct(plot.df$Uhrzeit)
Spielverlauf$Uhrzeit<-as.POSIXct(Spielverlauf$Uhrzeit)
Tweet-Daten und Spielereignis-Daten zusammenfügen
Mittels „plyr“ werden die dataframes anhand der gemeinsamen Uhrzeiten in einen gemeinsamen dataframe überführt. Das all.x=TRUE Argument ist wichtig, da somit alle Einträge aus dem plot.df dataframe übernommen werden. Dies entspricht einem „left join“. Das Bild hinter diesem Link verdeutlicht das.
library(plyr)
daten<- merge(plot.df,Spielverlauf,by="Uhrzeit", all.x=TRUE)
Wenn wir den Text zu jedem Spielereignis plotten würden, würde man von der eigentlichen Grafik nichts mehr sehen. Daher filtere ich alle Spielereignisse raus, die nicht während der 10% der stärksten Tweetminuten geschrieben wurden.
daten$Ereignis<-as.character(daten$Ereignis)
daten3 <- daten %>% mutate(cumdist = cume_dist(desc(Freq)),
top = as.character(ifelse(cumdist < 0.1, Ereignis, NA))) %>%
select(Uhrzeit,Freq, Ereignis, top)
Visualisieren
Endlich können wir die Daten visualisieren. Der dataframe „daten“ enthält die Spalten „Uhrzeit“, „Freq“,“Ereignis“ und „Top“. „Top“ enthält dasselbe wie „Ereignis“, allerdings nur für die 10% der Minuten mit der größten Tweetproduktion.
Grafik 1

ggplot(daten3,aes(Uhrzeit,Freq)) +geom_line()+ geom_area(fill="darkgreen",alpha=.8)+theme_bw()
Grafik 2
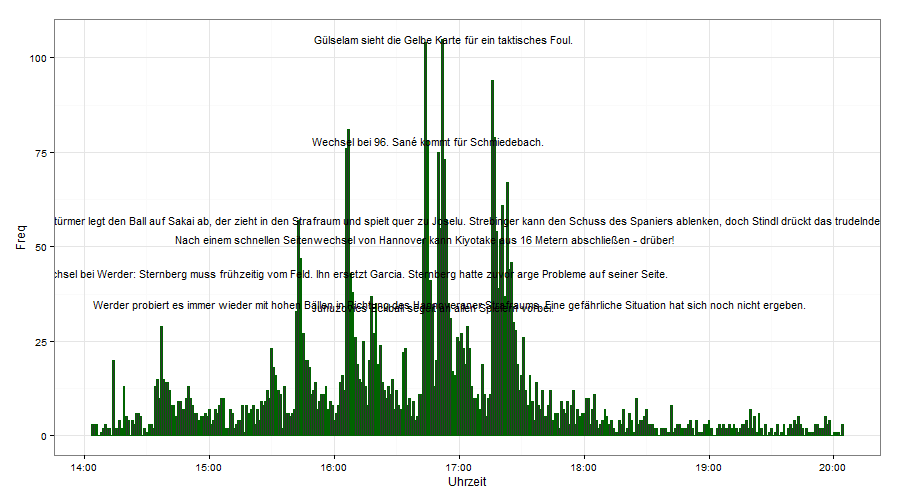
ggplot(daten3) + geom_bar(aes(Uhrzeit,Freq),stat="identity",colour="darkgreen") + geom_text(aes(Uhrzeit,Freq,label=top),size=4)+ theme_bw()
Grafik 3
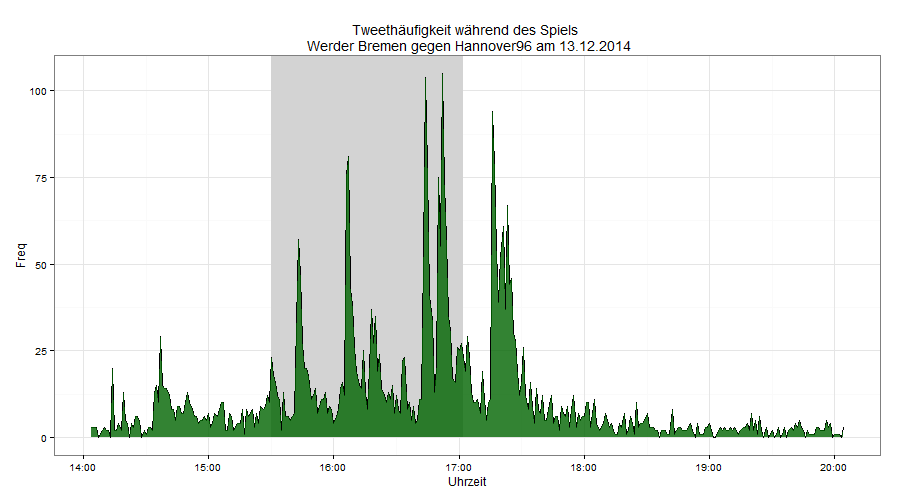
xmin<-as.POSIXct(strptime("2014-12-13 15:30:00", "%Y-%m-%d %H:%M:%S"))
xmax<-as.POSIXct(strptime("2014-12-13 17:02:00", "%Y-%m-%d %H:%M:%S"))
Halbzeit<-as.POSIXct(strptime("2014-12-13 16:15:00", "%Y-%m-%d %H:%M:%S"))
ggplot(daten3,aes(Uhrzeit,Freq))+geom_rect(data=NULL,aes(xmin=xmin,xmax=xmax,ymin=0,ymax=Inf),alpha=0.9,fill="lightgrey")+geom_rect(data=NULL,aes(xmin=Halbzeit,xmax=Halbzeit,ymin=0,ymax=Inf),fill="black")+geom_line(colour="black") + geom_area(fill="darkgreen",alpha=.8) +theme_bw()