
Twitter-mining mit R – Teil 4: Sentiment Analysis mit R
Sentiment Analysis ist die „Stimmungsanalyse“ eines Textes. Beispielsweise werden Tweets dahingehend klassifiziert, dass sie eher positiven oder negativen Inhalt haben. Hierfür gibt es zwei Ansätze:
- per Lernalgorithmus
- lexikalisch
Ich verwende in diesem Beispiel die zweite Variante und werde einen lexikalischen Abgleich vornehmen, um die Tweets entsprechend ihres Wortinhalts als eher positiv oder eher negativ einzuordnen. Hierfür verwende ich eine Funktion von Jeffrey Breen:
score.sentiment = function(sentences, pos.words, neg.words, .progress='none')
{
require(plyr)
require(stringr)
# we got a vector of sentences. plyr will handle a list
# or a vector as an "l" for us
# we want a simple array ("a") of scores back, so we use
# "l" + "a" + "ply" = "laply":
scores = laply(sentences, function(sentence, pos.words, neg.words) {
# clean up sentences with R's regex-driven global substitute, gsub():
sentence = gsub('[[:punct:]]', '', sentence)
sentence = gsub('[[:cntrl:]]', '', sentence)
sentence = gsub('\\d+', '', sentence)
# and convert to lower case:
sentence = tolower(sentence)
# split into words. str_split is in the stringr package
word.list = str_split(sentence, '\\s+')
# sometimes a list() is one level of hierarchy too much
words = unlist(word.list)
# compare our words to the dictionaries of positive & negative terms
pos.matches = match(words, pos.words)
neg.matches = match(words, neg.words)
# match() returns the position of the matched term or NA
# we just want a TRUE/FALSE:
pos.matches = !is.na(pos.matches)
neg.matches = !is.na(neg.matches)
# and conveniently enough, TRUE/FALSE will be treated as 1/0 by sum():
score = sum(pos.matches) - sum(neg.matches)
return(score)
}, pos.words, neg.words, .progress=.progress )
scores.df = data.frame(score=scores, text=sentences)
return(scores.df)
}
Die obige Funktion übernimmt die Kategorisierung. Nun fehlen noch die Tweets, für die ein Sentiment-Score errechnet werden soll und jeweils eine Wortliste mit positiven und negativen Worten, die hierfür verwendet wird.
Verbindung zu Twitter herstellen, Tweets abfragen und Wortliste downloaden
#----------------------------------------------------- # --- Mit Twitter verbinden --- #----------------------------------------------------- library(twitteR) # Authentifizierungsschlüssel eingeben api_key <- "**************************" api_secret <- "***************************" access_token <- "*****************************" access_token_secret <- "******************************" setup_twitter_oauth(api_key,api_secret,access_token,access_token_secret)
#Tweet-Abfrage
hashtag.tweets = searchTwitter('LeaveItIn2014', n=900)
Tweets.text = laply(hashtag.tweets,function(t)t$getText())
#Emoticons in Tweets verursachen manchmal Probleme
tryTolower = function(x)
{
# create missing value
# this is where the returned value will be
y = NA
# tryCatch error
try_error = tryCatch(tolower(x), error = function(e) e)
# if not an error
if (!inherits(try_error, "error"))
y = tolower(x)
return(y)
}
Tweets.text<-sapply(Tweets.text, function(x) tryTolower(x))
#Wortliste downloaden
pos <-scan('https://raw.githubusercontent.com/jeffreybreen/twitter-sentiment-analysis-tutorial-201107/master/data/opinion-lexicon-English/positive-words.txt', what='character', comment.char=';')
neg <- scan('https://raw.githubusercontent.com/jeffreybreen/twitter-sentiment-analysis-tutorial-201107/master/data/opinion-lexicon-English/negative-words.txt', what='character', comment.char=';')
[/code]
<strong>Sentiment Score der Tweets berechnen und visualisieren</strong>
[code language="r"]
#--Sentiment 1 berechnen
analysis<-score.sentiment(Tweets.text, pos, neg)
table(analysis$score)
library(ggplot2)
ggplot(analysis,aes(score)) + geom_bar(stat="bin",binwidth=1) +theme_bw() +scale_fill_brewer() + ggtitle("Sentiment-Score zu Hashtag `LeaveItin2014`")
Dies erzeugt folgende Grafik: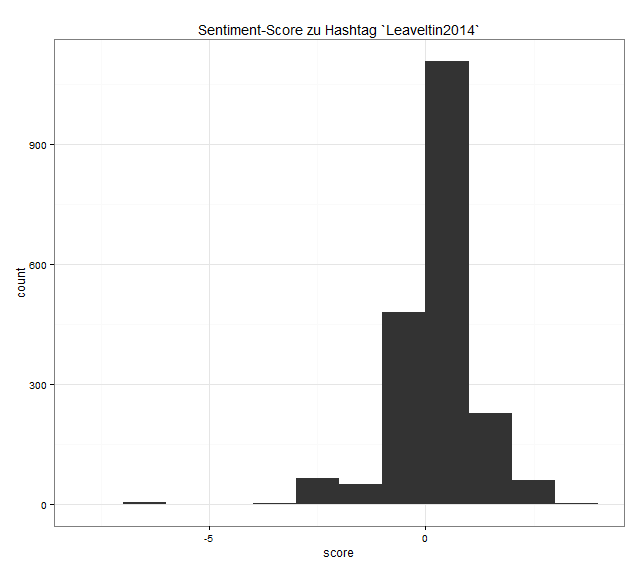
Unter dem Hashtag „Leaveitin2014“ twittern Menschen darüber, welche Erfahrungen, Handlungsweisen oder Einstellungen sie nicht mit ins neue Jahr nehmen wollen. Hier wird also eine Art subjektiver Bilanz für 2014 gezogen und in Vorsätze für 2015 umgewandelt. Der Graph ist so, wie er sich hier darstellt nicht ganz korrekt. Der größte Balken steht für den Sentiment-Score von Null, ist hier jedoch auf der X-Achse zwischen 0 und 1 angesiedelt. Besser wäre es, er würde durch die „0“ in der Mitte geteilt. Das werde ich bei Gelegenheit noch nachbessern.
Der Sentiment-Score der Tweets zum Hashtag „Leaveitin2014“ reicht von -7 (sehr negativ) bis 3 (moderat positiv). Null ist der Mittelpunkt.
Sentiment-Score Vergleich von „climate change“ und „global warming“
Inspiriert von diesem Artikel wollte ich einmal testen, ob tweets sich hinsichtlich ihres Sentiment-Scores unterscheiden, wenn sie „climate change“ oder „global warming“ als Begriffe für dasselbe Phänomen verwenden.
#Tweets besorgen
library(plyr)
library(dplyr)
warming.tweets = searchTwitter('global warming', n=900)
warming.text = laply(warming.tweets,function(t)t$getText())
change.tweets = searchTwitter('climate change', n=900)
change.text = laply(change.tweets,function(t)t$getText())
#Formatierung
tryTolower = function(x)
{
# create missing value
# this is where the returned value will be
y = NA
# tryCatch error
try_error = tryCatch(tolower(x), error = function(e) e)
# if not an error
if (!inherits(try_error, "error"))
y = tolower(x)
return(y)
}
warming.text<-sapply(warming.text, function(x) tryTolower(x))
change.text<-sapply(change.text, function(x) tryTolower(x))
#sentiment score berechnen
warming<-score.sentiment(warming.text, pos, neg)
change<-score.sentiment(change.text, pos, neg)
#Daten zusammenfügen und aggregieren
warming$Begriff<-c("global warming")
change$Begriff<-c("climate change")
all.scores<-rbind(change,warming)
all.scores$Begriff<-as.factor(all.scores$Begriff)
#Plotten
ggplot(all.scores) + geom_bar(aes(x=score,y=..count..),binwidth=1) + facet_grid(Begriff~.)+theme_bw()
table(all.scores$score)
Dies erzeugt die folgende Grafik:
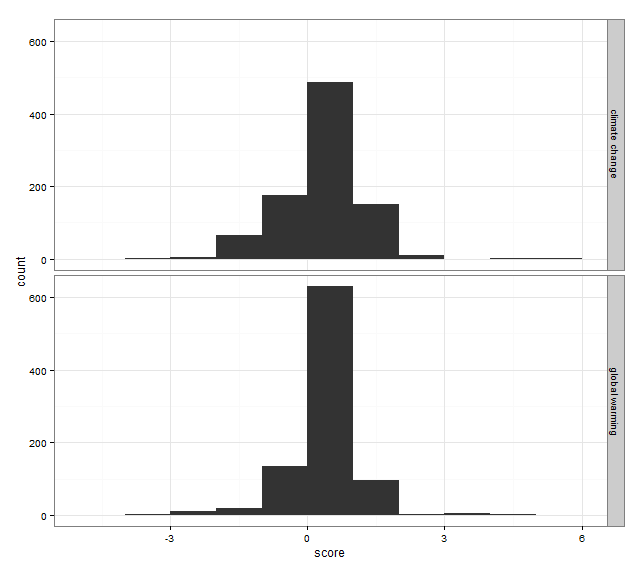
Vergleich der Sentiment-Scores der Begriffe „climate change“ und „global warming“. Jeweils 900 Tweets als Datengrundlage.
Wie man sieht, gibt es hinsichtlich der Sentiment-Scores beider Begriffe kaum einen Unterschied. In beiden Balkendiagrammen hat der Sentiment-Score von Null den größten Anteil. Es gibt darüberhinaus in beiden Diagrammen eine leichte Tendenz zu negativen Inhalten.
Das hier, soll nur als erster Kontakt mit solchen Auswertungen verstanden werden. Wenn man in die obige Frage viel Zeit investiert, erhält man spannende Einsichten: Climaps.EU – State of Climate Change in digital media
Im nächsten Blogeintrag (Teil 5) zeige ich, wie man in einer Grafik die globale Verteilung der Follower eines Twitteraccounts visualisieren kann.
[Hier soll später noch eine Comparison Wordcloud mit Sentiment +/- als Gruppierungsvariable]